
任何 Python 物件都可以當串列 (list) 的各個元素。
串列(list)跟字串(string)的中文名稱中,都有個「串」字,對於初學者而言滿容易搞混。
不過如果看英文名稱的話,應該就會分得很明白了。list 有「清單」的意思,串列列出清單,而 string 是「串」的意思,串出文字。
Python串列(list)以 [ ] 中括號來表示,例如 [‘a’, ‘b’, ‘c’] 就是一個簡單的串列,它的項目包括三個字串 ‘a’, ‘b’, ‘c’,並以逗號隔開,位置(index)分別是 0、1、2。
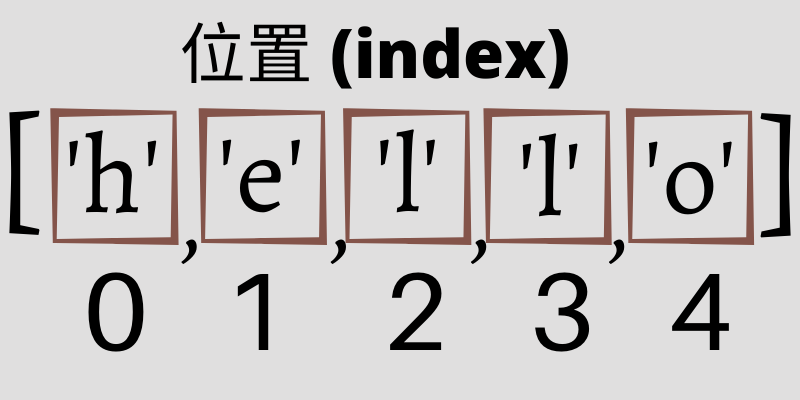
關於位置(index),在〈Python 觀念〉這篇文章「從0開始起算」段落中,針對位置的算法有做詳細說明。這滿重要的,寫程式的過程中,你會常常用到。
Python串列的特性
串列特性包括:
- 可以儲存多個資料
就像建立一個資料清單,可以放入很多資料,相同的資料可以重複出現。 - 屬於序列結構
序列,指的是串列內的值有順序性,所以可以使用各種有關順序的方法(Method) 進行操作;結構,指的是資料結構(data structure)是電腦中儲存、組織資料的方式。 - 值是可變的(mutable)
可以刪除、增加、修改串列的值,可以更動串列內的各個項目。
怎麼建立Python串列呢?
直接加上中括號建立串列
建立Python串列,最直觀的方式就是直接以中括號包覆你要建立串列的內容。
下方的例子,我們將想將三個字串'steak', 'apple', 'soup'建成一個名為dinner的串列,打出 ['steak', 'apple', 'soup']後,將這個串列指派給你設定的變數名稱 dinner ,便建立一個名為 dinner 的串列了。
>>>dinner = ['steak', 'apple', 'soup'] 使用 list() 建立串列
透由list() 函式,將字串轉換成各別字元組成的串列。
>>>print(list('steak'))
['s', 't', 'e', 'a', 'k']也可以將 tuple 轉換為串列,下方的例子就將名為 breakfast 的 tuple 轉換為串列。
>>>breakfast = ('sandwich', 'milk')
>>>print(list(breakfast))
['sandwich', 'milk']而如果 list() 的括號內,什麼都沒有填入,則會生成一個空串列。
>>>print(list())
[]使用字串方法 split()建立串列
split() 這個字串方法(Method),可以將字串(string) 拆開回傳串列(list)。
split()有兩個參數,如果第2個參數沒有輸入,就默認為 -1,看到幾個分隔的依據就切割出幾個項目。
split(分隔的依據, 分成幾個)
以下方命名為 date 的字串為例,以 / 為切割點,將字串分拆為三個項目。因為第二個參數沒有輸入,所以分割全部。
>>>date = '2020/11/25'
>>>print(date.split('/'))
['2020', '11', '25']當你只要將字串分拆為兩個項目,可以在引數輸入 1,回傳的串列就只會填到 1 的位置,串列內便只在 0、1 兩個位置上有項目。
>>>date = '2020/11/25'
>>>print(date.split('/',1))
['2020', '11/25']小結
當你在編寫程式碼時,你可以用前述三種操作來建立Python串列:
- 使用中括號 [ ]
- 使用
list()函式 - 使用字串方法
split()
假如你現在要建立一個1到9,這9個字的字串串列(串列內含的東西是字串),依照小結所列的建立串列操作,你可以這麼做:
>>>['1', '2', '3', '4', '5', '6', '7', '8', '9']
>>>list('123456789')
>>>'1 2 3 4 5 6 7 8 9'.split()你可以試試,返回的值都是一樣的串列,你可以視情況使用對你來說比較有利、方便的操作來建立串列。
串列基本操作
使用len()函式取得串列的項目數
在len()函式的括號內,放入要計算串列項目的串列名稱,或者直接把串列放進去也可以。
>>>letters = ['a', 'b', 'c', 'd' ,'e' ,'f', 'g']
>>>print(len(letters))
7
>>>print(len(['a','b']))
2使用index()方法,找到項目的位置
因為是方法(Method),所以要將 index() 放在串列名稱之後來使用,串列與方法中間還要以一句點連接。
>>>red = ['flower', 'blood', 'hair']
>>>print(red.index('blood'))
1使用 in、 not in 運算子檢查是否存在
使用 in 來檢測時,如果檢測的項目存在,會回傳True,不存在則回傳False。
用not in來檢測時以此類推,不存在回傳True,存在時則回傳False。
接下來的例子,就使用命名為 red 的串列來說明。
>>>red = ['flower', 'blood', 'hair']
print('flower' in red)
True
>>>print('dog' in red)
False
>>>print('flower' not in red)
False
>>>print('dog' not in red)
True使用 count()方法,計算項目出現的次數
運用 count()方法可以很快速地幫你算出,指定的項目出現幾次,如果串列中沒有這個項目就會回傳 0。
>>>red = ['flower', 'blood', 'hair', 'hair', 'hair']
>>>print(red.count('hair'))
3
>>>print(red.count('tomato'))
0串列的提取、改變、增減、排序操作
除了前述的基本操作,串列的操作主要可分為 5 個面向,利用這樣的分類,幫助你知道有那些工具可以運用於串列上。
- 把資料拿出來
- 改變資料內容
- 增加資料
- 刪除資料
- 排序資料
接下來就依照這五個面向,分別介紹串列中提取、改變、增加、刪除、排序的操作。
提取串列中的項目
Python串列像是經過排序的清單,有順序性,所以可以依照各個項目存在的位置,提取所需要的資料。
[ ]填入位置,只能是整數,且不能超出串列內項目的數量。
提取單一個項目
在串列名稱後方加上一個中括號,填入提取的資料所在位置。
舉例來說,建立一個名為 letters 的串列,並且依序印出在位置 0、5、-1 的項目。
>>>letters = ['a', 'b', 'c', 'd' ,'e' ,'f', 'g']
>>>print(letters[0])
>>>print(letters[5])
>>>print(letters[-1])
a
f
g-1 位置指的是最後一個項目,只要你是針對最後一個項目,都可以用 -1 來操作。當然空串列就無法找到 -1 位置的項目,只有空串列不適用。
如果使用浮點數(float) 或者提取的位置範圍超過了,Python 都會回傳錯誤給你。
當你填入浮點數,就是有小數點的數字,會出現 TypeError。
>>>letters = ['a', 'b', 'c', 'd' ,'e' ,'f', 'g']
>>>print(letters[1.8])
print(letters[1.8])
TypeError: list indices must be integers or slices, not float而當位置超出範圍時,會出現 IndexError。下方的例子中,範圍只能是 -7 ~ 6,負數的部分,是從串列尾端代表 -1 ,右至左 -1 、-2…這樣數過來。
>>>letters = ['a', 'b', 'c', 'd' ,'e' ,'f', 'g']
>>>print(letters[10])
print(letters[10])
IndexError: list index out of range提取子串列
使用 slice 提取串列中的子串列,於提取單一項目一樣,在串列名稱後方加上中括號,並在括號內要提取的起點與終點,更講究的時候,還可以要求固定間隔多少項目進行提取。
中括號以冒號區隔,分別填入
[起點 : 終點 : 間隔]
這個中括號內只有冒號不能省略,其他都可以省略。如果省略冒號,就等於是提取一個單一項目,而不是子串列。
口語一點就是,[2] 是拿 index 在2的值;[2:] 則是從index 2的位置上切一刀,取一整段的值。
省略時,預設值為 [0: 提取到最後一個:1]
值得注意的是,當你設定終點時,提取出來的項目會是起點位置到終點前一個項目,也就是你設定終點位置的項目不會提出來。
下方的例子中 red 串列有 6 個項目
>>>red = ['flower', 'blood', 'hair', 'cake', 'bird', 'cloud']位置分別為 0、1、2、3、4、5,當你將終點設為5的時候,並不會提取最後一個項目 ‘cloud’,而只會提取項目到 n-1。
>>>red = ['flower', 'blood', 'hair', 'cake', 'bird', 'cloud']
>>>print((red[0:5:2]))
['flower', 'hair', 'bird']
>>>print((red[:5:2]))
['flower', 'hair', 'bird']
>>>print((red[:5:]))
['flower', 'blood', 'hair', 'cake', 'bird']
>>>print(red[::3])
['flower', 'cake']
>>>print(red[:])
['flower', 'blood', 'hair', 'cake', 'bird', 'cloud']除此之外,提取的子串列可以選擇由右到左這個方向,只需在間隔值參數,填上負號 – 即可,下方例子我們填入 -1,便由右邊往左邊提取子字串了。
>>>red = ['flower', 'blood', 'hair', 'cake', 'bird', 'cloud']
>>>print((red[::-1]))
['cloud', 'bird', 'cake', 'hair', 'blood', 'flower']
使用 slice 時可以指定無效的範圍,不會造成例外,只會取得最接近的值。
多重指定 (multiple assignment)
利用串列,一次指定多個值給不同的變數,變數的數量需與串列中的項目數量一致。
>>>red = ['flower', 'blood', 'hair']
>>>buy, donate, dye = red
>>>print(buy, donate, dye)
flower blood hair當然也可以一個一個慢慢指定,得到的結果是一樣的。
>>>red = ['flower', 'blood', 'hair']
>>>gift = red[0]
>>>afraid = red[1]
>>>prefer = red[2]
>>>print(gift, afraid, prefer)
flower blood hair改變串列內的項目
運用提取項目的操作,將希望改變的項目指派給串列
下方的例子中,將 red 這個串列,位置 1 的字串,把原本的 ‘blood ‘ 改為 ‘dog’,印出來的串列確實在位置 1 上出現 ‘dog’ 字串。
>>>red = ['flower', 'blood', 'hair', 'cake']
>>>red[1] = 'dog'
>>>print(red)
['flower', 'dog', 'hair', 'cake']除了可以一次改變一個項目外,也可以運用 slice,同時改變多個項目。
下面的例子中,要求在位置 1 到 3 個項目中,以 2 為間隔值由左向右的替換項目為 ‘dog’ 與 ‘tomato’。
>>>red = ['flower', 'blood', 'hair', 'cake', 'bird', 'cloud']
>>>red[1:4:2] = ['dog', 'tomato']
>>>print(red)
['flower', 'dog', 'hair', 'tomato', 'bird', 'cloud']增加串列的項目
使用 * 運算子,重複多個串列
在串列至後加上 * 及要重複的次數。
>>>print(['Yes! '] * 3)
['Yes! ', 'Yes! ', 'Yes! ']使用 + 運算子,將串列相加
在串列之後輸入 + ,及要增加的串列。
>>>print(['Yes! '] * 3 + ['very good!'])
['Yes! ', 'Yes! ', 'Yes! ', 'very good!']使用 extend() 方法,將串列相加
extend 的英文意思是擴展、增加長度,使用這個方法時,我們將順序放在前的的串列作為擴充的主體,在該串列上使用 extend(),要被增加上去的串列放在括號內。
>>>red = ['flower', 'blood', 'hair', 'cake', 'bird', 'cloud']
>>>add_red = ['dog','tomato']
>>>red.extend(add_red)
>>>print(red)輸出的結果
['flower', 'blood', 'hair', 'cake', 'bird', 'cloud', 'dog', 'tomato']使用 insert() 方法,將項目插入指定位置
在 insert() 的括號內填入兩個引數,第一個代表位置,第二個代表要插入的項目。
insert()是專屬於串列的方法,只能用在串列上,其他資料型態都不行。
>>>red = ['flower', 'blood', 'hair']
>>>red.insert(0, 'tomato')
>>>print(red)
['tomato', 'flower', 'blood', 'hair']位置如果超過串列的項目數量,會直接將要插入的值放在最後。
>>>red = ['flower', 'blood', 'hair']
>>>red.insert(10, 'tomato')
>>>print(red)
['flower', 'blood', 'hair', 'tomato']使用 append() 方法,將項目加到串列尾端
在append() 的括號內填入要增加在串列尾端的值。
append()是也專屬於串列的方法,只能用在串列上,其他資料型態都不行。
>>>red = ['flower', 'blood', 'hair']
>>>red.append('tomato')
>>>print(red)
['flower', 'blood', 'hair', 'tomato']當插入的值也是串列的時候,會變怎樣呢?
>>>red = ['flower', 'blood', 'hair']
>>>red.append(['tomato', 'cake'])
>>>print(red)
['flower', 'blood', 'hair', ['tomato', 'cake']]跟你想的一樣嗎?插入的項目就是一個串列,而這樣有一層一層的感覺的資料結構,就是巢狀結構
串列可以容納各種 Python 的物件,在串列中放入串列也是可以的。
刪除串列項目
用 del 陳述句刪除項目
在del後方說明要刪除的項目,在知道項目的位置(index)時,就可以在串列中把該項目刪除。
del不是函式(Function),也不是方法(Method),不需要使用括號 (),只要把要執行的動作敘述出來就可以,所以就叫del為陳述句。
例子中,名字叫作 red 的串列有 5 個字串項目,我們使用 del 陳述句,把位置 0 的 ‘flower’ 字串刪除。
>>>red = ['flower', 'blood', 'hair', 'hair', 'hair']
>>>del red[0]
>>>print(red)
['blood', 'hair', 'hair', 'hair']使用 del陳述句來刪除項目,你需要知道項目的位置,如果不知道變無法正確的刪除。
用 remove() 方法刪除項目
當你只記得項目是什麼,但不知道位置時,可以使用remove()方法來刪除項目,在括號中填入你要刪除的值即可。
如果你要刪除的項目,在串列中有很多個,remove()只能刪除找到的第一個。
下方的例子中,’hair’ 只被刪除了一次。
>>>red = ['flower', 'blood', 'hair', 'hair', 'hair']
>>>red.remove('hair')
>>>print(red)
['flower', 'blood', 'hair', 'hair']用 pop() 方法取出項目,並刪除
使用pop()方法來刪除項目,也需要知道要刪除的項目在哪裡,位置(index)是什麼?
pop()的括號內填入位置,就可以刪掉那個位置的值。
如果你什麼都沒有填的話,預設值式 -1,Python 會把尾端的項目取出並且刪除。
為什麼要說取出呢,因為你印出 red.pop(位置),會印出刪除的項目,而不是 None。
你看,下方的例子中 pop()就提取出 blood,讓我們可以用 print() 函式把它印出來。
而 red 串列中的 blood。
>>>red = ['flower', 'blood', 'hair', 'hair', 'hair']
>>>print(red.pop(1))
blood
>>>print(red)
['flower', 'hair', 'hair', 'hair']用 clear() 方法把全部的項目刪光(Python 3.3後加入)
使用clear()可以把串列中的所有項目刪除,回傳一個空串列。
>>>red = ['flower', 'blood', 'hair']
>>>red.clear()
>>>print(red)
[]用 slice 刪除項目
前面介紹的改變串列所使用的 slice,也可以刪除項目,把項目改變為空的串列就可以了。
>>>red = ['flower', 'blood', 'hair', 'hair', 'hair']
>>>red[:2] = []
>>>print(red)
['hair', 'hair', 'hair']排序資料
運用 reverse()方法將順序倒過來,原串列改變
串列是有順序性的資料型態,如果你想把順序整個顛倒過來,可以使用reverse() 方法將串列的順序反轉,原串列被改變,順序倒過來了。
>>>red = ['flower', 'blood', 'hair', 'cake', 'tomato']
>>>red.reverse()
>>>print(red)程式碼執行後的結果:
['tomato', 'cake', 'hair', 'blood', 'flower']使用reversed()函式產生相反順序的迭代器,原串列不變
想讓串列順序相反,你還可以使用reversed()函式,和前面的reverse()方法差了字尾的d,你有發現嗎?
reversed()函式除了字尾多了一個d,還有兩點不同點:
reversed()函式不會改變原有串列。- 返回的值是迭代器(iterator),需使用
list()函式將之變為串列。
用相同例子來說明:
>>> red = ['flower', 'blood', 'hair', 'cake', 'tomato']
>>> newRed = list(reversed(red))
>>> print(newRed)程式碼執行後的結果:
['tomato', 'cake', 'hair', 'blood', 'flower']用 sort() 方法就地改變排序,原串列會改變

當串列中單純只有數值或只有字串,可以使用 sort()方法改變串列的排序,預設的排序是數值由小到大,字母依「ASCII」所對應的數值,由小到大,升序排序。
從下方「ASCII」表格中,我們可以看到大寫 A 的內碼是 65(看十進位那行),小寫 a 的內碼是97,以此類推,所以大寫字母會排在小寫字母之前。
如果希望降序排序,就是有大到小排序,在sort()的括號中填入 reverse = True,像這樣 sort(reverse = True),就可以讓字串降序排序了。
先舉兩個單純的排序例子,串列中只有數值:
>>>number = [5, 7, 9, 1, 3, 55]
>>>number.sort()
>>>print(number)
[1, 3, 5, 7, 9, 55]串列中只有字串:
>>>red = ['flower', 'blood', 'hair', 'cake', 'tomato']
>>>red.sort()
>>>print(red)
['blood', 'cake', 'flower', 'hair', 'tomato']sort 方法有三個要點要留意:
1. 會直接改變串列的排序。
2. 當串列的項目中混有數值、字串時,Python無法排序。
3. 排序的依據是「ASCII」,大寫字母會排在小寫字母之前,也就是小寫的 a 會排在大寫 Z 之後。
先來看看當串列中混有數值與字串時,Python會有什麼反應。
>>>number = [5, 7, '9', 1, 3, 55]
>>>number.sort()
>>>print(number)
number.sort()
TypeError: '< ' not supported between instances of 'str' and 'int'果然,顯示 TypeError 這個錯誤提示,要排序的串列中,不可以混合數值與字串, ‘9’ 是字串不是數值。
而當串列中有字母大小寫不同的字串時,是怎麼排列的呢?
>>>letters = ['Z', 'A', 'a', 'z', 'q', 'Q']
>>>letters.sort()
>>>print(letters)
['A', 'Q', 'Z', 'a', 'q', 'z']Python 依據「ASCII」將大小寫字母分別排序。
如果希望 A、a 不論大小寫,都可以排在前頭,可以結合字串方法 str.lower,把字母統一轉換為小寫讓 Python 去排序,當然使用 str.upper 也可。
這個方式不會改變串列內的值,只是在排序時會統一將值視為小寫或大寫。
>>>letters = ['Z', 'A', 'a', 'z', 'q', 'Q']
>>>letters.sort(key = str.lower)
>>>print(letters)
['A', 'a', 'q', 'Q', 'Z', 'z']使用 sorted() 函式回傳改變後的副本,原串列不變
sorted() 函式與剛剛介紹的sort()方法外觀極為相像,只是函式多了ed。
sorted() 以升序排序,在括弧內有四個參數。
(串列, cmp比較的函數 , 比較的元素 key = None , 排序規則 reverse = False)
cmp本文不談,先使用其他參個變數來排序,sorted()函式並不會改變原本的串列排序,而是做一個副本進行排序。
>>>letters = ['Z', 'A', 'a', 'z', 'q', 'Q']
>>>print(sorted(letters, key = str.lower, reverse = True))
['Z', 'z', 'q', 'Q', 'A', 'a']
>>>print(letters)
['Z', 'A', 'a', 'z', 'q', 'Q']複製串列
當我們要操作串列但又不想動到串列,造成串列的改變,可以將串列的值複製後指派給一個新的變數,新的變數就會是一樣的串列,就好像你平時用 word 編輯文件時,另存新檔的情況。
用 list() 複製串列
像在建立串列一樣,在 list() 函式的括號中放入要複製的串列,再指派給新的變數。
>>>red = ['flower', 'blood', 'hair']
>>>red_copy = list(red)
>>>print(red)
['flower', 'blood', 'hair']
>>>print(red_copy)
['flower', 'blood', 'hair']
>>>print(id(red))
2610472
>>>print(id(red_copy))
2780008
用 slice 複製串列
運用slice[:]一刀不切,將串列再指派給新的變數。
>>>red = ['flower', 'blood', 'hair']
>>>red_copy = red[:]
>>>print(red)
['flower', 'blood', 'hair']
>>>print(red_copy)
['flower', 'blood', 'hair']用 copy() 方法製作副本
使用copy()方法(Method)複製串列,將複製後的串列指派給新的變數。
>>>red = ['flower', 'blood', 'hair']
>>>red_copy = red.copy()
>>>print(red)
['flower', 'blood', 'hair']
>>>print(red_copy)
['flower', 'blood', 'hair']匯入copy 模組,用 deepcopy() 函式製作深度複製的副本
有copy()這個複製的方法(Method),為何還有deepcopy()函式呢?
(長得很像的東西又一個方法、一個函式了,考驗人的記憶力阿…..)

deepcopy()加了一個 deep,顧名思義,這是一個從骨子裡全部都複製起來的意思。
對於串列中還存放了串列的資料,要使用deepcopy()才可以將串列才可以完全的複製。
>>>red = ['flower', 'blood', [55, 6]]
>>>red_list = list(red)
>>>red_slice = red[:]
>>>red_copy = red.copy()
>>>print(red)
>>>print(red_list)
>>>print(red_slice)
>>>print(red_copy)
['flower', 'blood', [55, 6]]
['flower', 'blood', [55, 6]]
['flower', 'blood', [55, 6]]
['flower', 'blood', [55, 6]]
成功複製後,只更動 red[0]、red[2][0] 的值,其他三個複製 red 串列的變數後變更嗎?
red[2][0] 是指,red 串列中,位置 2的項目內,在位置 0 的值,先找到 red[2],再看這個位置的項目內位置 0 的值,下方的例子中red[2][0] 是一個數值 55。
我們將 red[0] 改為 100、red[2][0] 的值改變為數值 88,剛剛複製 red 的三個變數值也變動了,但只有 [2][0] 的地方跟著變動,[0] 並沒有變動。
>>>red[0] = 100
>>>red[2][0] = 88
>>>print(red)
>>>print(red_list)
>>>print(red_slice)
>>>print(red_copy)
[100, 'blood', [88, 6]]
['flower', 'blood', [88, 6]]
['flower', 'blood', [88, 6]]
['flower', 'blood', [88, 6]]list()、slice、copy()的複製都屬於淺層的複製,當資料只有一層時,不會有問題,複製後的串列不因原本複製的本體而變動,所以 red[0]從 ‘flower’ 變為 100,red_list、red_slice、red_copy 這三個串列位置 0 的值,仍維持不變。
但當資料多於一層時,例如串列中還包含了串列,淺層的複製無法深入到第二層以上。這樣多層的概念,也稱之為巢狀。
這時候就需要deepcopy(),才可以將每一個層次的資料都複製到新的變數中。
使用前你必須先匯入copy模組,才會有deepcopy()函式功能。
>>>import copy
>>>red = ['flower', 'blood', [55, 6]]
>>>red[0] = 100
>>>red[2][0] = 88
>>>print(red)
[100, 'blood', [88, 6]]
>>>red_deepcopy = copy.deepcopy(red)
>>>print(red_deepcopy)
[100, 'blood', [88, 6]]
>>>print(red_copy)
['flower', 'blood', [55, 6]]使用串列時的常見錯誤
IndexError
初學Python 串列(list),容易忘記位置(index)的算法是從0開始,當提取串列中的資料,指定的位置卻超出範圍,就會出現IndexError。
例如,在名為red的串列中,你要印出’hair’這個項目,但以為它的位置是3,導致Python 回覆你錯誤。
>>>red = ['flower', 'blood', 'hair']
>>>print(red[3])
print(red[3])
IndexError: list index out of rangeout of range 就是超出範圍的意思。
為什麼呢?因為 ‘hair’ 的位置是 2 才對。
>>>red = ['flower', 'blood', 'hair']
>>>print(red[2])
hair串列還有一個很常見的操作,是使用 for 及 in 製作的迴圈(loop)進行迭代(iteration),你可以在這篇文章看到說明〈Python for 迴圈(loop)的基本認識與7種操作〉,迭代串列(list)可以搭配本文的函式、串列方法運用,端看你的需求是什麼囉。
如果想瞭解更多串列的觀念與操作,推薦閱讀《精通 Python》、《Python自動化的樂趣》這兩本書,都有單獨針對字串做詳細的說明及練習。
延伸閱讀:




使用前你必須先匯入 copy 模組,才會有 deepcopy() 函式功能。
>>>print(red)
[100, ‘blood’, [88, 6]]
>>>print(red_deepcopy)
[‘flower’, ‘blood’, [55, 6]]
請問>>>print(red_deepcopy) 這段是否有誤?
一直測試不出來
已修正 感謝您的留言
import copy
red = [‘flower’, ‘blood’, [55, 6]]
red_deepcopy = copy.deepcopy(red)
red[0] = 100
red[2][0] = 88
print(red)
print(red_deepcopy)
感謝整理與分享!
不客氣,希望對於學習Python有幫助。